Qwen 2.5 Omni support has arrived in llama.cpp, marking a notable step toward more versatile, multimodal open-source AI. This integration enables input processing of both audio and vision—though, for now, audio output is not supported (more: url). Qwen 2.5 Omni’s inclusion reflects the growing demand for models capable of handling diverse data types beyond plain text, echoing the industry-wide shift toward richer, context-aware applications. While the lack of audio output limits some use cases, the ability to ingest both images and audio opens doors for experimental research and practical tools in accessibility, content tagging, and real-time transcription.
Simultaneously, the open-source ecosystem around LLMs continues to accelerate. Unsloth’s Magistral-Small-2506 offers a quantized, efficient reasoning model with a large context window (up to 128k tokens, with recommended use at 40k for best performance), making it suitable for local deployment on consumer hardware. Built on top of Mistral Small 3.1, it supports dozens of languages and demonstrates strong results on benchmarks like AIME and GPQA (more: url1, url2). These advances underscore the rapid democratization of sophisticated language models, enabling more users to experiment with long-context and multilingual applications without cloud dependencies.
Meanwhile, the dots.llm1 series introduces a large-scale Mixture-of-Experts (MoE) model, activating 14B of its 142B parameters per inference. Impressively, it matches the performance of much larger models like Qwen2.5-72B despite using only high-quality, non-synthetic pretraining data (more: url). The release of intermediate checkpoints offers valuable transparency into model training dynamics—a welcome trend for reproducibility and research.
Open-source tooling for local LLM experimentation is becoming increasingly user-friendly. Tome, a new desktop app, simplifies the process of connecting to local or remote LLMs with Model Context Protocol (MCP) support. Users can chat with models, install MCP servers with a single click, and avoid the configuration headaches of Docker or complex scripts. The focus is on accessibility, aiming to lower the barrier for beginners while keeping the door open for future power-user features (more: url).
The MCP ecosystem itself is evolving rapidly, with community projects like a “memory MCP” that acts as a private, user-controlled contextual memory bank for AI applications. This tool allows personal data and context to remain local and secure, sidestepping concerns about user profiling by large AI providers (more: url). Such privacy-focused solutions respond directly to growing skepticism about centralized data collection.
On the infrastructure side, the LLM Gateway project is transitioning from a simple prompt-routing tool to a robust data-plane for agents. This upgrade enables agent-to-agent and user-to-agent prompt routing, clarifying, triaging, and monitoring tasks in a language- and framework-agnostic way. The move reflects a maturation in agent-based applications, addressing the “plumbing” that often hinders scalable, reliable deployments (more: url).
Practical deployment of large models often hinges on efficient conversion and quantization. The new rvn-convert tool, written in Rust, streamlines the process of converting Hugging Face SafeTensors to the GGUF v3 format used by llama.cpp. Unlike previous Python-based tools, rvn-convert boasts fast, single-shard and multi-shard support, memory-mapped processing to avoid RAM spikes, and robust handling of tokenizer embeddings—all without Python dependencies (more: url). This reduces friction in model deployment pipelines, especially for those running on resource-constrained hardware.
On the quantization research front, GuidedQuant (arXiv:2505.07004) introduces a novel approach to post-training quantization (PTQ) for LLMs by integrating end-loss guidance into the quantization objective. This method is tested on models like Qwen3, Gemma3, and Llama3.3 at 2–4 bit precision, offering improved accuracy compared to traditional layer-wise PTQ. The team also debuts LNQ, a non-uniform scalar quantization algorithm that guarantees a monotonic decrease in quantization error (more: url). Lower-bit quantization is crucial for running LLMs efficiently on commodity hardware, and methods that preserve accuracy without retraining are highly sought after.
Expanding model context windows remains a hot pursuit for local LLM enthusiasts. Community experiments with llama.cpp and models like Gemma 3 27B demonstrate context windows as large as 100k tokens, though achieving high throughput (tokens per second) remains a challenge (more: url). Performance tuning is highly hardware- and parameter-dependent, with users reporting practical trade-offs between speed, memory usage, and accuracy. For most, the sweet spot is still well below the theoretical maximum—underscoring the gap between model capability and real-world usability.
In the productivity tooling space, local LLMs are being harnessed for automated debugging. One project leverages Ollama models with Retrieval-Augmented Generation (RAG) across the user’s codebase to auto-fix terminal errors—claiming “scary good” results, especially with Claude 4 integration (more: url). The workflow is entirely local, preserving privacy and enabling rapid feedback. As LLM-powered assistants become more capable, such tools hint at a future where debugging and code maintenance are less tedious, though claims of full automation should be treated with cautious optimism.
Ablation studies with Gemma 3 27B, using synthetic data generated from Claude Sonnet 4, explore the trade-offs between few-shot prompting and LoRA-based fine-tuning for real-world, multi-objective tasks (more: url). While the experiment is described as informal, it addresses a central question for practitioners: can smaller, open models be made competitive with proprietary giants via distillation, or does in-context learning suffice for practical deployment? Early findings suggest that well-crafted synthetic datasets can significantly close the performance gap, though fine-tuning remains essential for mastering complex, structured objectives. These hands-on reports provide valuable guidance for teams seeking to balance cost, privacy, and model capability.
Beyond AI models, foundational infrastructure continues to evolve. GitLab’s engineering team recently slashed their repository backup times from 48 hours to just 41 minutes by addressing a 15-year-old O(N²) algorithm in Git core (more: url). This fix not only reduces operational costs and risks for GitLab, but also benefits any organization managing large codebases—a reminder that classical algorithmic improvements remain highly impactful.
Meanwhile, the open-source programming language Carbon aims to offer a modern, memory-safe successor to C++, with strong performance and seamless interoperability. While still experimental, Carbon’s design addresses long-standing pain points in C++ evolution and migration, such as technical debt and slow language progress (more: url). For developers invested in performance-critical systems, languages like Carbon could provide a much-needed path forward—provided their ecosystems mature and adoption hurdles are overcome.
On the desktop side, GNOME is moving toward stronger dependencies on systemd, specifically leveraging systemd-userdb for dynamic user account allocation in multi-seat and remote login scenarios. While GNOME has historically allowed alternative init systems, this shift signals a consolidation around systemd for core functionalities, potentially complicating deployment on non-systemd distributions (more: url). The change exemplifies the tension between standardization and flexibility in the Linux ecosystem.
Security and data privacy remain perennial concerns. The streamcrypt Go library introduces a seamless, streaming AES-GCM encryption layer for any io.Reader/io.Writer interface, supporting huge datasets with minimal memory usage and no external dependencies (more: url). Its append-safe and compression-friendly design makes it an attractive drop-in for secure data pipelines, especially in cloud and big data contexts.
In graphics and AI research, a minimalist reimplementation of 3D Gaussian Splatting (3DGS) using NVIDIA Warp demonstrates how modern differentiable rendering techniques can be made accessible without complex CUDA setups. This project enables experimentation on both CPU and GPU, lowering the barrier for those interested in neural graphics and parallel rendering (more: url). For text-to-image synthesis, the fuse-dit project explores deep fusion between large language models and diffusion transformers, offering scalable training recipes for TPUs and emphasizing reproducibility (more: url).
Finally, in quantum metrology, a novel experiment demonstrates that squeezing the vacuum state in an atomic clock—essentially adding an average of 0.75 atoms—can improve the clock sensitivity of a 10,000-atom ensemble beyond the standard quantum limit (SQL) by over 2 dB (more: url). This underscores how advances in quantum information can yield practical gains in precision measurement, with implications for next-generation timekeeping and fundamental physics tests.
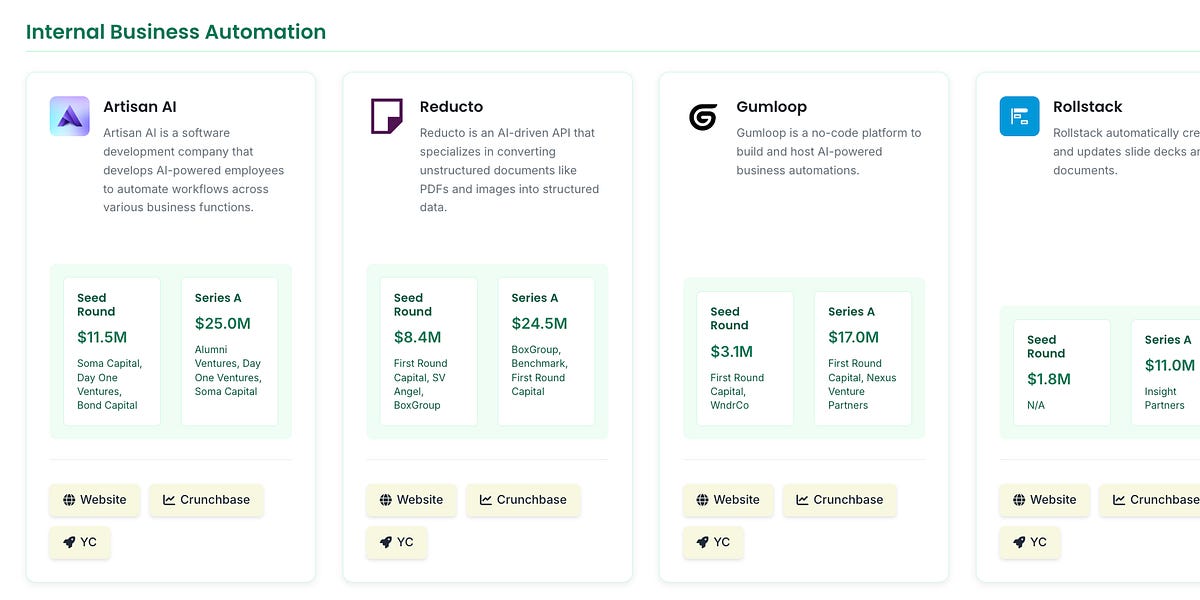
Analyzing the startup landscape post-ChatGPT, only 2.4% of Y Combinator companies from the first four AI-boom batches have raised Series A rounds so far—a figure skewed by the short time window since founding and the reporting lag for large initial rounds. While this topline number may seem low, it reflects the reality that most startups are still maturing, and the AI market remains in rapid flux (more: url). The analysis highlights a few early breakout successes but cautions against over-interpreting short-term funding trends as indictments or endorsements of the accelerator model.
In open research, the dots.llm1 team’s release of intermediate training checkpoints sets a commendable standard for transparency. Likewise, papers on combinatorial algebra, such as new frameworks for 0-Hecke modules and type-B quasisymmetric functions, continue to push the boundaries of mathematical and representational understanding (more: url). This culture of open experimentation and sharing—spanning from AI models to mathematical theory—remains one of the most powerful engines for progress in technology and science.