Running large language models (LLMs) locally is becoming increasingly viable, even with modest hardware. A recent proof-of-concept demonstrates that a 123-billion-parameter model can be run on a sub-€300 setup: a refurbished ThinkCentre, 64GB RAM, and a consumer SSD, using llama-server on Linux. The catch? Response times are measured in days—32 hours for 123B, or a more practical 1.5–2 hours for 32B. The experiment focused on letter-length exchanges, leveraging an 8K token context window and heavy use of SSD swap, with careful overprovisioning to extend SSD lifespan (more: url). While this setup is far from real-time, it underscores how LLM accessibility is decoupling from expensive GPUs—at least for those willing to wait.
At the other end of the spectrum, power users are assembling dual RTX 5090 rigs with 128GB VRAM, able to process 50K-word prompts with Qwen 32B in minutes. These systems, costing upwards of $6,400, turn formerly overnight tasks into five-minute jobs, making them attractive for workloads involving sensitive data or large, complex reports. Builders note that even less expensive dual 3090 systems can achieve 80% of the performance for about a third of the cost, broadening access to local, high-performance AI (more: url).
Despite the hardware advances and proliferation of open models, a recurring question in the community is: why aren’t more real, niche tools being built atop local LLMs? While models under 3B parameters are now practical for many tasks, bottlenecks remain—compute, distribution, and especially user experience. The technical work is there, but the leap from wrappers and playgrounds to polished, user-facing products is still rare (more: url).
Evidence is mounting that LLMs can serve as practical agents for desktop automation and accessibility. A recent demo used LLaMA 3-8B running locally on an Apple M2 chip to interpret natural language instructions and plan macOS UI actions. The pipeline: Ollama generates a JSON plan from plain English, the macOS Vision framework locates UI elements, and the Accessibility API executes actions, with a feedback loop for error correction. In a real-world test (“rename every PNG on Desktop to yyyy-mm-dd-counter, then zip them”), the system correctly executed five out of six steps, missing only a modal dialog. The codebase (Python + Swift) is open source, and suggestions are sought for improving UI grounding and reducing hallucinated steps (more: url).
This experiment highlights both the promise and the remaining hurdles of local LLM-powered automation. While accuracy is impressive for a small model, reliably interfacing with unpredictable UIs remains challenging. Nonetheless, the ability for users to automate desktop workflows with on-device models—without sending data to the cloud—has clear privacy and accessibility benefits.
Qwen models are rapidly gaining traction in the local LLM scene, with many users noting their dominance in fine-tuning and leaderboard results. The Qwen3 Embedding series, particularly the 8B variant, currently tops the MTEB multilingual leaderboard (score: 70.58 as of June 2025). These models excel at text embedding, reranking, code retrieval, and support over 100 languages. The 0.6B reranker offers strong performance with a 32K context window, flexible vector definitions, and user-defined instructions for task adaptation (more: url1, url2).
Another notable release is Sarvam-M, a 24B open-weights, hybrid reasoning model built on Mistral. It introduces a “think” mode for complex reasoning and a “non-think” mode for efficient general conversation. Sarvam-M shows exceptional gains: +20% on Indian language benchmarks, +21.6% on math, and +17.6% on programming, with a standout +86% improvement in romanized Indian math tasks. Its focus on Indic scripts, English, and cultural values makes it particularly relevant for multilingual users seeking both reasoning and conversational capabilities (more: url1, url2).
Meanwhile, KumoRFM introduces a new paradigm: Foundation Models for relational data. Unlike LLMs trained on unstructured text, KumoRFM is designed to make instant predictions over multi-table relational databases using in-context learning. Its Relational Graph Transformer enables reasoning across tables, and evaluations on 30 tasks show it outperforms both feature engineering and deep learning baselines by 2–8%. With fine-tuning, improvements reach 10–30%, and speed is orders of magnitude better than conventional approaches. This could mark a turning point for structured data AI, an area previously dominated by manual engineering (more: url).
Running large models locally still presents practical puzzles. One user reports that, despite running larger models like Gemma3:27B and Qwen3:32B entirely on a 3090 GPU, the smaller OpenEuroLLM-Italian (12.2B) only uses 18% of GPU memory, with the rest on CPU. This suggests model-specific quirks in memory allocation or framework compatibility, a reminder that not all quantized or pruned models behave predictably across hardware (more: url).
On the software side, compatibility headaches persist. A user working on quantum deep learning with JAX and Pennylane on Ubuntu 25.04 finds that, despite having an NVIDIA GPU, JAX falls back to CPU due to missing CUDA-enabled jaxlib. This highlights the ongoing friction in aligning ML libraries, CUDA versions, and Linux distributions—a seemingly perennial issue for anyone outside the “blessed” software stack (more: url).
Meanwhile, developers continue to push model context windows to their limits. Dual 5090 rigs are now routinely handling 50K-word prompts, and users are experimenting with 8K and even 32K contexts for detailed, multi-turn conversations and document analysis. The tradeoff between speed, memory, and context size is ever-present, but the baseline for “local” LLM capability is rising rapidly.
AI coding tools and developer workflows are evolving quickly. Anthropic’s Claude 4 models (Opus 4 and Sonnet 4) set new standards for coding and reasoning, with support for tool use (e.g., web search), parallel tool execution, and advanced memory for agent workflows. The Claude Code tool, now generally available to Pro, Max, Team, and Enterprise users, offers direct terminal access, background tasks via GitHub Actions, and native IDE integrations (VS Code, JetBrains). New Anthropic API features include a code execution tool, Model Context Protocol (MCP) connector, Files API, and prompt caching, enabling more powerful AI agents (more: url1, url2).
Yet, skepticism remains within the programming community. One developer’s essay, “The Copilot Delusion,” argues that AI pair programmers (and even some human ones) often lack true understanding, leading to code that works by accident rather than design—“the programming equivalent of punching your TV to make the static stop.” The critique is not just about competence, but about the erosion of programming as a craft, where deep understanding is replaced by shallow, outcome-driven edits (more: url).
Security is another pressing concern, especially as “vibe coding”—rapid prototyping with AI-generated code—becomes the norm. A new CLI tool aims to eliminate “secret sprawl,” the accidental leakage of API keys and credentials in codebases. The tool manages secrets across environments and teammates, reducing the risk of hardcoded keys, forgotten .env files, and Slack leaks. As more non-developers and solo builders enter the field, such tools could become crucial for maintaining security without DevOps expertise (more: url).
Open source tooling continues to benefit from AI integration. ProKZee, a cross-platform desktop application for HTTP/HTTPS traffic interception, now features AI-powered analysis via ChatGPT, alongside classic features like traffic manipulation, fuzzing, and out-of-band testing. Built with Go and React, it runs on Windows, macOS, and Linux, and supports Docker-based development for rapid iteration. This kind of AI augmentation is increasingly common in security and network analysis tools, streamlining workflows that once required significant manual effort (more: url).
For Go developers, stripedvitro/utilities offers a suite of command-line tools to streamline code generation, error handling, documentation, and shell scripting, demonstrating that even traditional languages are seeing renewed automation and productivity gains through small, focused utilities (more: url).
Cloud platforms are racing to provide developer-friendly AI infrastructure. Google Cloud’s generative-ai repository showcases the latest Gemini 2.5 Pro and Flash models, with production-ready agent templates, notebooks, and code samples to accelerate deployment on Vertex AI. The Agent Development Kit (ADK) and Agent Starter Pack address common operational challenges, from deployment and evaluation to observability and customization. While positioned as demonstrative and not officially supported, these resources lower the barrier for teams to build and manage generative AI workflows at scale (more: url).
On the creative side, AI-generated 3D modeling is now accessible to anyone with ChatGPT or open-source alternatives. A workflow demonstrated by 3D AI Studio allows a user to sketch an object, generate a finished image via prompt, convert it to a 3D mesh in under a minute, and 3D print the result—no manual poly modeling required. Free alternatives like Stable Diffusion + ControlNet or open-source 3D AI models (e.g., Trellis) can replicate the process, but ChatGPT remains the most user-friendly for many (more: url).
Recent research offers glimpses into the next generation of hardware and fundamental science. One paper proposes a 0-$\pi$ superconducting qubit realized in a single Josephson junction, leveraging spin-orbit coupling and Zeeman splitting to achieve parity protection without increased device complexity. This could help stabilize quantum information at the hardware level, a step toward more robust quantum computing (more: url).
Another study demonstrates the creation of 100-kilotelsa magnetic fields using femtosecond lasers and paisley-patterned targets. Such fields, comparable to those in black hole accretion disks, enable laboratory astrophysics experiments on magnetic reconnection and high-energy density physics, with robust target designs that can extend field lifetimes into the picosecond scale (more: url).
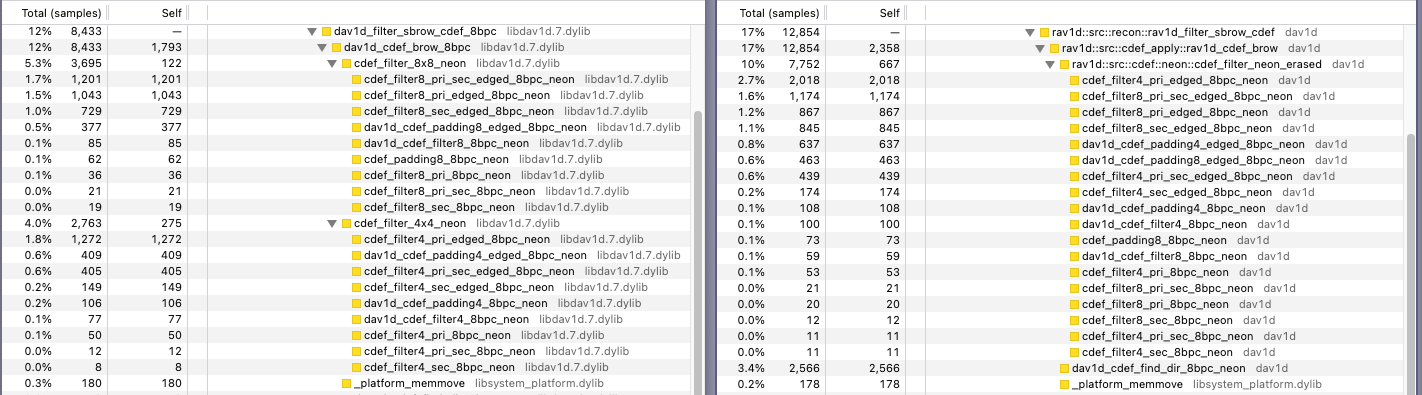
In the realm of software, a careful performance analysis of the Rust-based rav1d AV1 video decoder yielded a modest but meaningful ~1% speedup on Apple M3 hardware, simply by comparing function-level performance with the original C implementation. While Rust still trails C by about 5% for this workload, the gap is narrowing, and the process illustrates the value of methodical profiling and cross-language optimization (more: url).