SAGA, the Semantic And Graph-enhanced Authoring project, has taken a significant leap in autonomous novel generation by deepening its integration of knowledge graphs and semantic context. The core innovation is the use of a Neo4j graph database, which now serves as the backbone for tracking intricate narrative elements—characters, world-building, plot progression, and dynamic relationships—far beyond what a simple database could offer. This enables a structured, canonical reference for the story, making it possible to maintain consistency and depth even as the narrative evolves (more: url).
A major advancement is SAGA’s “hybrid context” generation for each chapter. By combining semantic similarity searches over previous content (using Ollama embeddings) with fact extraction from the knowledge graph, the system ensures that the local LLM both remembers the narrative tone and adheres strictly to established story facts. This hybrid approach addresses two persistent weaknesses of LLM-based writing: narrative drift and factual inconsistency.
Revision and evaluation have also been upgraded. Patch-based revision allows for targeted fixes instead of blunt rewrites, and a suite of specialized agents now evaluate drafts for plot coherence, thematic depth, and world continuity. The WorldContinuityAgent, in particular, cross-references the knowledge graph to catch inconsistencies that might otherwise slip through. These improvements move SAGA closer to being a true collaborative partner for complex, long-form creative writing, underpinned by both structured data and deep language understanding.
Recent community experiments underscore the rapid progress in running large language models (LLMs) locally, especially with full GPU acceleration. Achieving llama-cpp-python with CUDA 12.9 on an RTX 5070 Ti (Blackwell architecture) demonstrates that even consumer hardware can now support efficient, high-throughput inference for quantized models like TinyLlama-1.1B-Chat (more: url). The key is building llama-cpp-python with the right CUDA flags (notably GGML_CUDA=on), and matching CUDA, driver, and architecture support. This approach offers a lightweight alternative to PyTorch, which still lacks support for the latest GPU architectures.
Performance tuning goes beyond hardware. With Qwen3-14B, users have achieved Aider Polyglot benchmarks rivaling GPT-4o by carefully managing quantization strategies and context window sizes—running the entire model on a 16GB GPU by quantizing the key-value (KV) cache. Notably, practical use cases often allow for multiple attempts at code generation, which can close the gap with top-tier cloud LLMs in real-world productivity (more: url).
However, not all software stacks are equally robust. Some users report that Ollama, despite detecting the GPU, refuses to offload even small models like Qwen3-0.6B, highlighting persistent quirks in GPU utilization across frameworks (more: url). The choice of hosting software remains fragmented, with Ollama praised for ease-of-use and CPU fallback, but Nvidia’s NIM/Triton touted for high throughput, parallelism, and multi-node scaling (more: url). Fine-tuning deployment for both VRAM and RAM is becoming an art form, especially for MoE (Mixture of Experts) models and large-context LLMs, as users seek to maximize context windows and model size within hardware constraints (more: url).
Tiny agents built on the Model Context Protocol (MCP) are gaining traction as a simple, effective way to automate browser and file control with local LLMs. These agents can be set up with just a CLI, a JSON config, and a prompt definition, working seamlessly with llama.cpp and openai-compatible servers (more: url). Notably, these agents can interact with browsers and local files directly, without relying on external APIs, thanks to MCP implementations like Playwright and mcp-remote.
The adoption of tiny agents marks a shift toward more modular, composable automation workflows, where local models take on roles traditionally reserved for cloud-based assistants. As the MCP ecosystem matures, expect further improvements in reliability, integration, and the breadth of supported tasks.
Fine-tuning and retrieval-augmented generation (RAG) are increasingly central to deploying effective local LLMs. Users setting up Ollama with Open WebUI on platforms like Coolify are exploring workflows where supervised fine-tuning is followed by RAG integration, enabling domain-specific knowledge to be injected into the model’s responses (more: url). The focus is on optimizing process efficiency, security, and seamless integration—reflecting a broader maturation of the local LLM deployment landscape.
Best practices now emphasize a careful balance: fine-tune only on relevant data, use RAG to supplement rather than overwrite model knowledge, and ensure system prompts and user access controls are robust. As open-source tooling improves, these hybrid approaches offer a compelling alternative to entirely cloud-based solutions, especially for privacy-sensitive or highly customized applications.
LLM coding abilities vary significantly by programming language, largely reflecting the composition of their training datasets. Languages like Python and JavaScript benefit from abundant open-source data, enabling LLMs to “dominate” front-end and scripting tasks. In contrast, less widely-shared languages such as Rust or C#—especially those prevalent in closed enterprise environments—see weaker performance (more: url).
User experiences confirm these trends: LLMs like ChatGPT-4o and Claude outperform Google’s Gemini for C# tasks, while Gemini excels with React.js. The lack of language-specific leaderboards highlights a transparency gap, making it difficult to compare models for particular programming languages. This variance underscores the need for more granular, polyglot benchmarks and for organizations to consider proprietary data access when training or selecting models for enterprise code generation.
Recent research is addressing two core technical challenges in LLM training: entropy collapse in reinforcement learning (RL) and memory limitations in long-context understanding.
The PRIME-RL/Entropy-Mechanism-of-RL paper tackles entropy collapse—a situation where the model’s output distribution becomes overconfident and loses diversity during RL fine-tuning. The authors empirically link entropy decline to the covariance between action probabilities and logit updates, and propose two mitigation strategies: Clip-Cov and KL-Cov. These methods restrict updates for high-covariance tokens, maintaining higher entropy and improving performance throughout training (more: url). Their approach is validated on scaling Qwen2.5 models from 7B to 32B parameters, suggesting broad applicability for RL-based LLM optimization.
Meanwhile, the ATLAS paper introduces a novel long-term memory module that optimizes memory not just for the latest input, but across current and past tokens. This overcomes the online-update limitations of modern recurrent models, enabling better performance on tasks with extreme context lengths—reportedly surpassing both Transformers and linear recurrent architectures on long-context benchmarks like BABILong (more: url). ATLAS’s approach of optimizing memory with respect to the full context, rather than just incrementally, represents a meaningful step toward more scalable and context-aware LLMs.
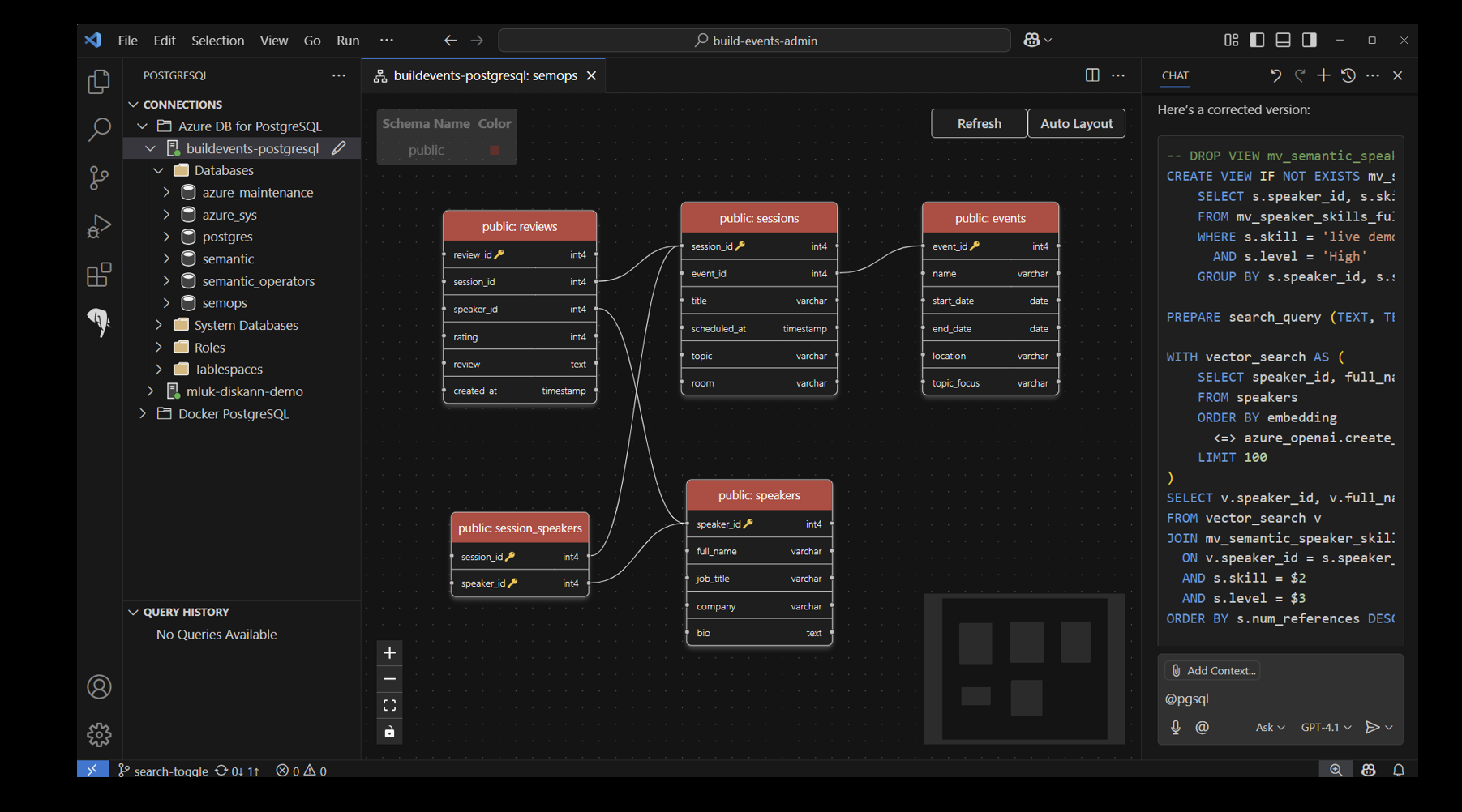
Developer tooling continues to evolve, with Microsoft announcing a new PostgreSQL extension for VS Code. This extension brings schema visualization, context-aware IntelliSense, and deep integration with the @pgsql GitHub Copilot agent directly into the code editor, addressing the persistent pain of context-switching between database management and application development (more: url). Features like Entra ID authentication and Azure integration further streamline workflows for developers working with Postgres.
In the AI video domain, BiliNote stands out as an open-source tool for generating structured, Markdown-formatted notes from videos on popular platforms like Bilibili, YouTube, and Douyin. It supports multimodal video understanding, audio transcription (with Fast-Whisper and CUDA acceleration), and integration with large language models for summarization (more: url). The ability to insert screenshots, jump to sections, and export notes in various formats (PDF, Word, Notion) makes it a powerful productivity enhancer for students and professionals alike.
Multimodal AI models are pushing the boundaries of visual understanding and generation. The UniVG-R1 project proposes a reasoning-guided MLLM for universal visual grounding, leveraging a new high-quality chain-of-thought (CoT) dataset and a difficulty-aware training strategy. UniVG-R1 achieves state-of-the-art performance across multiple grounding benchmarks, demonstrating strong generalizability and reasoning capabilities (more: url).
For style transfer and visual consistency, OmniConsistency introduces a model that learns style-agnostic consistency from paired stylization data, supporting a wide range of visual styles (more: url). This makes it easier to generate images that retain content while flexibly adapting to different artistic styles.
On the video front, Tencent’s HunyuanVideo-Avatar brings high-fidelity, audio-driven human animation to life, supporting multiple characters and precise emotion alignment. Innovations like the character image injection module and audio emotion module enable dynamic, emotion-controllable multi-character dialogue videos that outperform previous state-of-the-art methods on both curated and wild datasets (more: url).
Despite online speculation, the Deno team reports surging adoption and doubled monthly active users since Deno 2’s release, crediting improved Node compatibility and streamlined developer experience. The reduction in Deno Deploy regions reflects pragmatic optimization for usage and cost, not a retreat from the platform’s ambitions (more: url).
In programming languages, a comparative study of five parallel functional array languages—Accelerate, APL, DaCe, Futhark, and SaC—finds that these languages can deliver performance on par with hand-optimized code, while offering much shorter and more understandable source code. This bodes well for the future of performance-portable, parallel programming, especially as GPUs and multicore CPUs become ubiquitous (more: url).
For those interested in the mathematical underpinnings of algorithms, a new series introduces programmers to enumerative combinatorics, beginning with integer partitions and compositions. This foundational knowledge is increasingly relevant in algorithm design, data science, and competitive programming (more: url).
Edge AI continues to gain traction, with even “pocket AI” devices now capable of recognizing cars in real-world environments, albeit with the occasional misclassification (more: url). These advances hint at the growing accessibility and practical utility of compact, deployable AI models.
At the other end of the spectrum, a real-time, software-defined GPU-based receiver has been demonstrated over a 10,000 km straight-line optical link, processing multi-level QAM signals in real time. This achievement highlights the exponential improvements in GPU computation and energy efficiency, positioning general-purpose GPUs as a flexible alternative to FPGAs and ASICs in high-performance networking and signal processing (more: url).